Your Data Warehouse is your Customer Data Platform
“The number of Active Customers in {crm platform} doesn’t match our {BI Dashboard}, I don’t trust it, please fix, thanks!”.
If you’ve worked with customer data in a scale-up or big tech company, chances are that you’ve encountered such a problem at least once.
In this article, I’m going to lay out the solution to this problem: a headless architecture that leverages the Data Warehouse to store and model data on top of which tools for different use cases are natively integrated.
This Infrastructure will reduce both direct and indirect MarTech costs and improve the efficiency and effectiveness of the stack by creating trust in consistent metrics across tools and simplifying the data integrations architecture.
Customer Data Struggles
Before diving into the solution proposed, we are going to dissect the problem that we are trying to solve.
Companies typically collect customer data from different sources (backend, frontend, 3rd parties), reverse ETL it in a CDP &/OR in the data warehouse where data is further modelled and then piped into several tools to be activated for marketing, personalisation and other use cases
A very abstract representation of your MarTech stack may look like this.
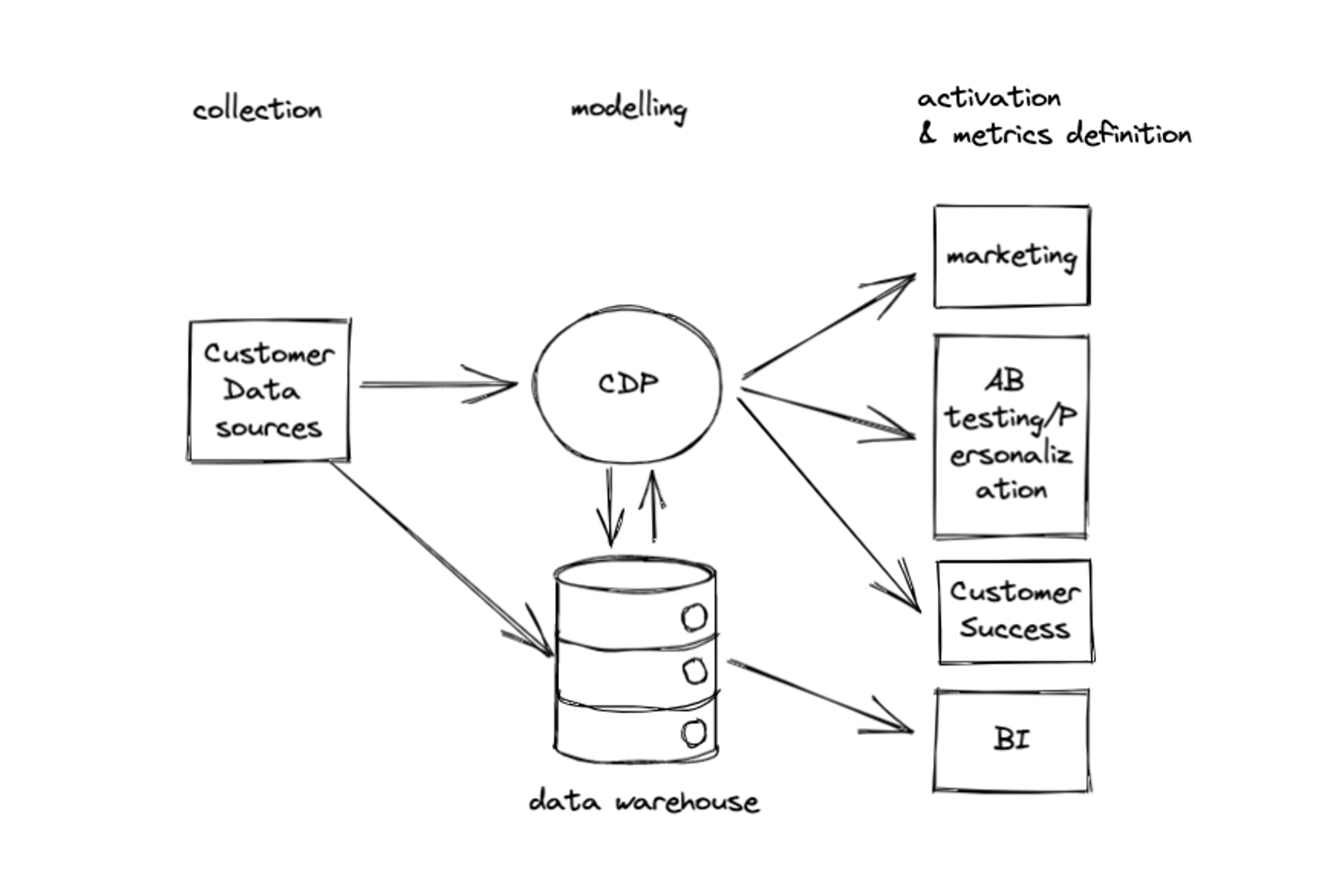
This architecture presents several inefficiencies that can be bucketed into two sets:
- Data modelling sprawl: data modelling and metric definition happen in tools that should be only for activation, there isn’t a single source of truth for metrics and audience definition (i.e “active users” metric is defined in both the CRM tool, the AB testing platform and the BI tool)
- High infrastructure costs: setting up the streaming/reverse ETL pipeline to send data from the data warehouse to the activation tools is a heavy burden. Reverse ETL tools such as Census and no code integrations are making the process smoother but the maintenance costs are still far from being low.
The Solution - A Warehouse-Native Headless Customer Data Platform
To solve these pain points we could transform our Data Warehouse (DWH) into a Headless Customer Data Platform. Here is how it would work.
We would get customer data from different sources in the DWH (eventually in a Data Lake first), model it via DBT or another Data Transformation framework, we would then define the metrics in a metric layer and finally, serve the activation layer for Marketing Automation, CRM, BI, Customer Success etc, etc…
It is called "headless" because it operates without a front-end user interface, allowing it to be easily integrated with a variety of applications and tools.
Rudderstack, a leading CDP vendor, has hinted to pivot in this direction. Their vision can be summarized by the following diagram.
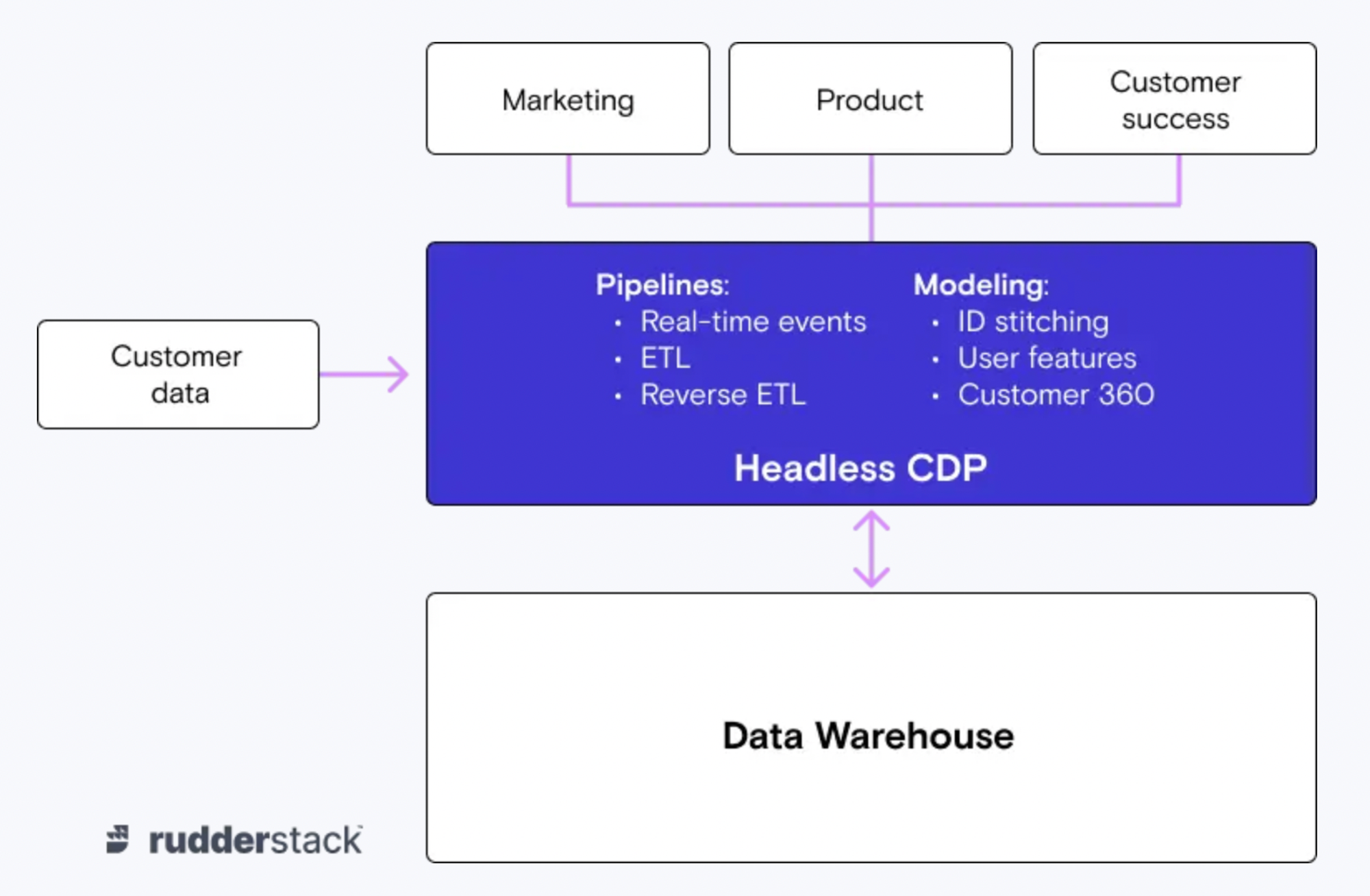
While I totally share the principles outlined by Soumyadeb Mitra, I think that we need to make two further steps to solve the above-mentioned problems:
- build a metric layer to unify metrics definition across tools. This new component of the Data Stack will become the single source of truth for all the tools that won’t need to redefine and compute the metric separately anymore.
- have the tools of the activation/delivery layer (i.e. the CRM) that sits directly on top of the data warehouse set up to also support live data streaming at scale for use cases that won’t work with batching (i.e. live product personalization). I think the market will push MarTech companies to move from Reverse ETL to this “Connected Application” approach trailblazed by MessageGears and SuperGrain which integrate natively with the Data Warehouse rather than requiring the customer to transfer their data to the app’s own servers.
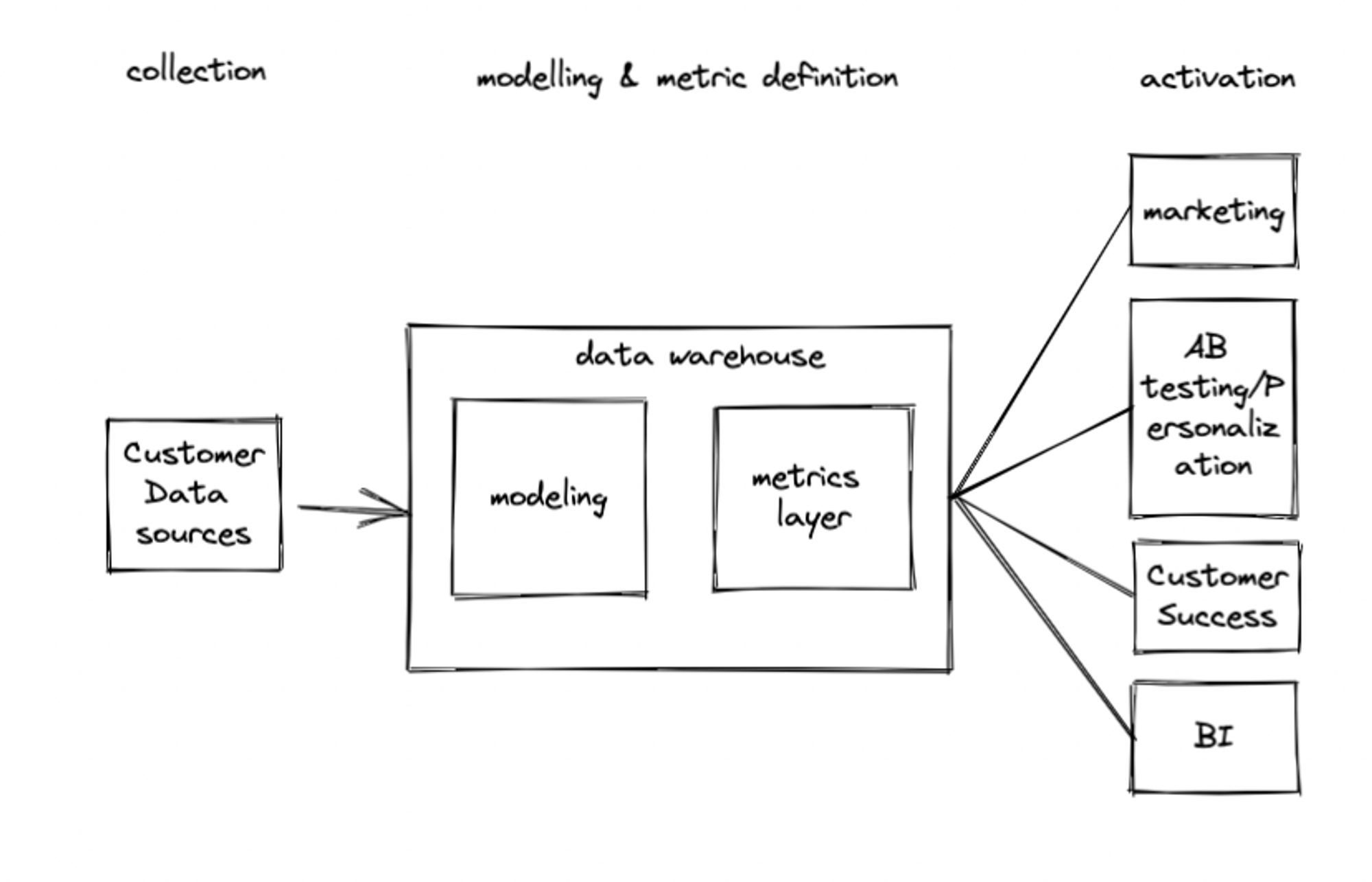
This architecture will drastically reduce the complexity of the Martech Stack and its cost:
- We are not going to pay for the data storage on 3rd parties CDP and tools
- Cut down engineering costs associated with building and maintaining the reverse ETL pipelines.
Furthermore, we won’t need to rely on the tools to know the state of your customers as you could build your own Observability layer on top of the data warehouse
The Road to Headless
It is becoming increasingly clear that owning and managing customer data is a core competence for modern businesses. This is because customer data is a valuable asset that can be used to personalize and improve the customer experience and drive business growth and innovation.
With a headless customer data platform, companies can retain full control over their customer data and use it to its full potential, while also benefiting from the scalability and flexibility of a warehouse-native solution.
On the other hand marketing tools and platforms will also need to adapt in order to remain competitive by creating warehouse-native integrations that allow them to easily connect to and leverage data from these platforms without relying on APIs or other reverse ETLs practices.
Thanks to Samuel Akinwunmi, Roger Pan and Gabriele Franco for reading drafts of this.